Google Research a présenté TurboQuant, un algorithme capable de compresser le cache des modèles d'IA à seulement 3 bits, contre 32 habituellement. Gain annoncé : six fois moins de mémoire et jusqu'à huit fois plus de vitesse sur GPU. En Bourse, Micron et Western Digital ont immédiatement décroché.
Micron et Western Digital dans le rouge
On commence par les dégâts les plus visibles. Quelques heures après la présentation de TurboQuant à la conférence ICLR 2026, les actions de Micron, Western Digital et SanDisk ont reculé. Le raisonnement des investisseurs tient en une phrase : si les modèles d'IA ont besoin de six fois moins de RAM pour fonctionner, la demande en puces DRAM risque de ralentir. Pour les opérateurs de datacenters, ça veut dire des factures en baisse. Pour les fabricants de composants, c'est un peu la douche froide, surtout que l'IA était devenue leur principal relais de croissance ces deux dernières années.
3 bits au lieu de 32, sans rien perdre
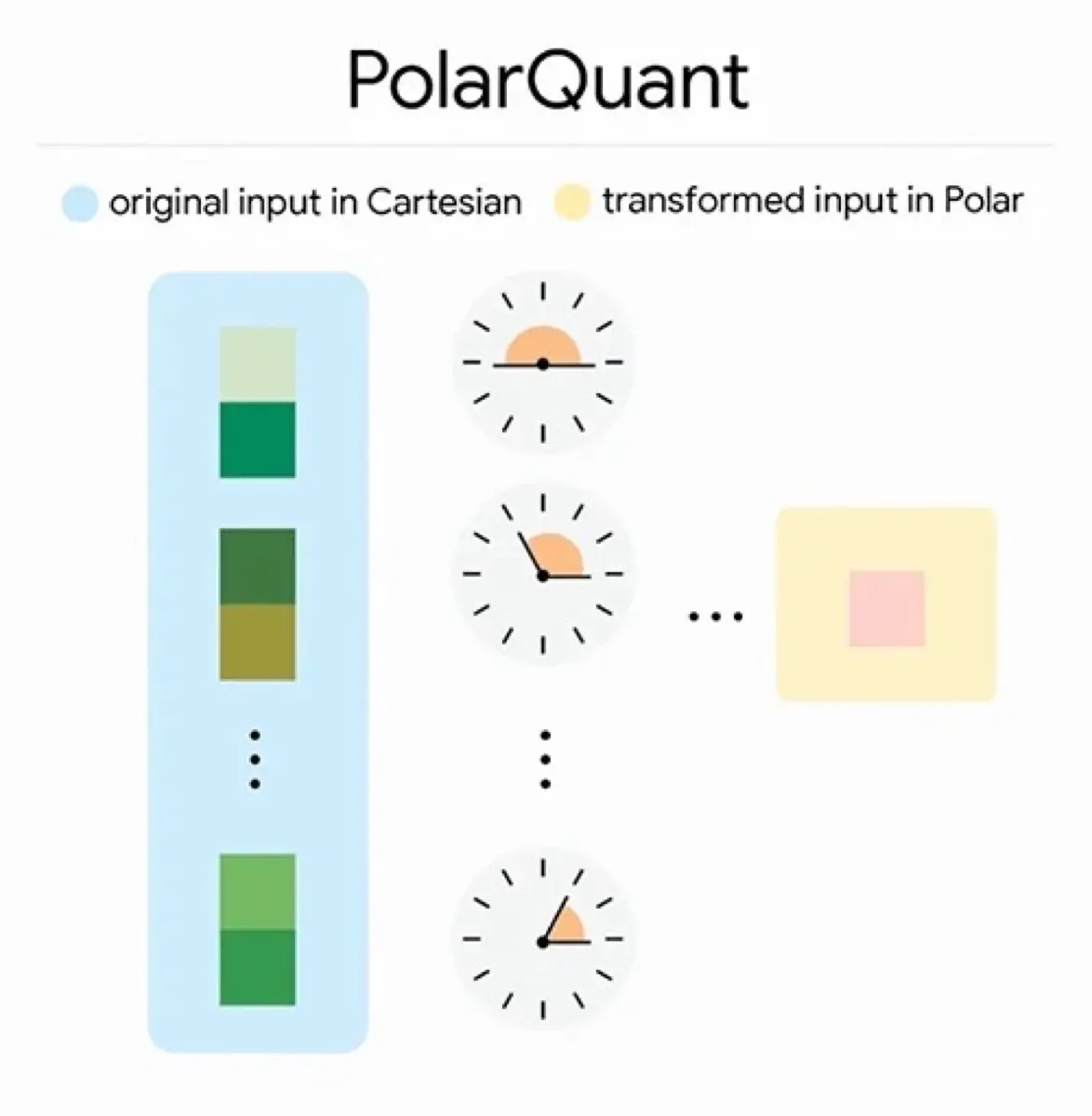
Côté technique, TurboQuant combine deux méthodes, et c'est un peu technique. PolarQuant transforme les données en coordonnées polaires, ce qui élimine les étapes de normalisation qui gaspillent de la mémoire. Et QJL corrige les erreurs résiduelles avec un seul bit en plus, sans aucun surcoût.
Google a testé tout ça sur Gemma, Mistral et Llama-3.1-8B avec des benchmarks de contexte long. Aucune perte de précision détectée, que ce soit en génération de code, en résumé ou en question-réponse. Sur les GPU Nvidia H100, la version 4 bits atteint un gain de vitesse jusqu'à huit fois supérieur au cache classique en 32 bits, c'est faramineux. Et surtout, pas besoin de réentraîner quoi que ce soit.
Qui en profite vraiment
Du côté des entreprises qui font tourner des modèles d'IA, c'est évidemment une très bonne nouvelle. Faire passer des contextes plus longs sur les mêmes machines sans acheter de mémoire supplémentaires, ça change la donne. Mais TurboQuant reste pour l'instant un papier de recherche présenté en conférence. Google ne dit rien sur une intégration dans Gemini ou dans ses services cloud, et entre un résultat de labo et un déploiement en production, on le sait, le chemin est rarement une ligne droite.
On en dit quoi ?
Difficile de nier que ça peut avoir un impact sur le marché. Un algorithme qui divise la mémoire par six sans sacrifier la qualité, ça va forcément bousculer les choses. Maintenant, la question c'est surtout ce que ça raconte sur l'avenir du marché de la RAM : si l'optimisation continue à ce rythme, Micron et consorts vont devoir trouver d'autres débouchés.